Who lies the most in US politics?
Most Americans, and anyone that follows US politics, will be aware of the tremendous changes and volatility that has struck the US political landscape in the past year. The ascent of Donald Trump from a billionaire entertainer to a fully fledged presidential candidate, alongside the unexpected popularity of Bernie Sanders and the nomination of Hillary Clinton as the first female presidential candidate, has catapulted this political season into one of the most entertaining, vicious and confusing year.
There have been a number of outlandish claims made recently, and one of the most important contribution of journalistic work is to comment and verify the veracity of statements made by those major political figures. One example of such work is published and maintained by Politifact, which regularly fact-checks statements made by a variety of sources, and displays the information in the following way:
I have casually browsed this website for a while, but I recently decided to try and surface some more information out of it. In particular, I wanted to:
- visualize a summary of the overall distribution of
statement veracityfor each individual. - build a web app to visualize direct comparisons of statements between individuals.
In the following post, I will collect and analyze some of the Politifact data, while also going through the steps that allowed me to create the web application displayed below
Obtaining data on political statements
To begin, I wrote a Python script to scrape all the required data on Politifact. The code snippet below iterates through each page of the Politifact website to extract and process the HTML source code containing the following data points:
- the individual that made the statement
- a URL to a headshot of the individual
- a categorical variable that states whether the statement is deemed to belong in one of the following categories (True; Mostly True; Half-True; Mostly False; False; Pants on Fire!; No Flip; Half Flip; Full Flop).
Below is the source code used to scrape the Politifact data
import urllib2
from bs4 import BeautifulSoup
import pandas as pd
import re
import json
import string
import itertools
def get_page_source(page):
'''
get HTML content of page
Params
args:
returns:
'''
try:
url = 'http://www.politifact.com/truth-o-meter/statements/?page={}'.format(page)
response = urllib2.urlopen(url)
page_source = response.read()
soup = BeautifulSoup(page_source, "html5lib")
return soup
except:
print "Could not obtain data for page {}".format(page)
return None
def extract_truth(table,
truth_meter,
image_source,
statement_text):
'''extract statement text, image of candidate and truth of statement'''
for truth in table:
fact = [item['alt'] for item in truth.findAll("img")]
images = [item['src'] for item in truth.findAll("img") if '.jpg' in item['src']]
statement = [item.text.strip() for item in truth.findAll("a", {"class": "link"})]
if fact[1] in truth_meter:
truth_meter[fact[1]].append(fact[0])
statement_text[fact[1]].append(statement[0])
else:
truth_meter[fact[1]] = []
truth_meter[fact[1]].append(fact[0])
statement_text[fact[1]] = []
statement_text[fact[1]].append(statement[0])
image_source[fact[1]] = images[0]
return truth_meter, image_source, statement_text
def process_page_data(soup,
truth_meter,
image_source,
statement_text):
try:
table = soup.findAll("div", {'class': 'scoretable__item'})
truth_meter, image_source, statement_text = extract_truth(table,
truth_meter,
image_source,
statement_text)
return truth_meter, image_source, statement_text
except:
return truth_meter, image_source, statement_text
def main():
truth_meter, image_source, statement_text = {}, {}, {}
for page in range(1, 198):
print page
soup = get_page_source(page)
if soup is not None:
truth_meter, image_source, statement_text = process_page_data(soup,
truth_meter,
image_source,
statement_text)
# process statement strings for R
statement_text_processed = {}
for k, val in statement_text.items():
val_no_punctuation = ["".join(l for l in sent if l not in string.punctuation) \
for sent in val]
val_lower = [sent.lower() for sent in val_no_punctuation]
if len(val_lower) > 1:
val_tokenized = ' '.join(val_lower).split(' ')
else:
val_tokenized = val_lower[0].split(' ')
statement_text_processed[k] = val_tokenized
with open('politifact_statements.txt', 'w') as outfile:
json.dump(truth_meter, outfile)
with open('politifact_statements_text.txt', 'w') as outfile:
json.dump(statement_text_processed, outfile)
df = pd.DataFrame.from_dict(image_source.items())
df.to_csv('politifact_image_source.csv', index=False, encoding='utf-8')
if __name__ == '__main__':
main()
A quick analysis of the Politifact data
With the data all gathered, I proceeded to perform a small analysis of the data. To begin, I looked at the different types of comments stated by the entities in the Politifact data. For example, what proportion of Donald Trump’s comments were True or False? Or what proportion of Donald Trump’s comments were a complete U-turn to his previous comments? For the sake of simplicity, I restricted the analysis to the 20 most common entities in the Politifact data, which produced the plot below:
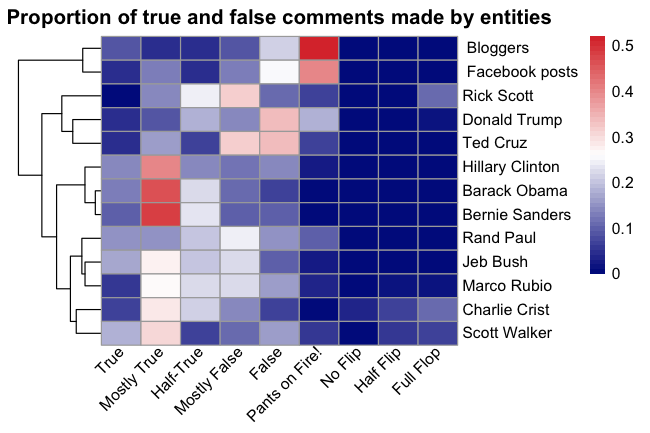
So what do we see? As expected, “facts” reported through blogs or social media networks (Facebook posts) tend to be predominantly false. On the reverse, Democrats (Hillary Clinton, Barack Obama, Bernie Sanders) tend to speak truthful comments. It is interesting to note that establishment Republicans such as Jeb Bush, Marco Rubio, Scott Walker and Rick Scott also trend towards true comments, but have a non-negligible proportion of “Mostly False” comments. The conservative-leaning democrat Charlie Crist follows a similar pattern. Finally, the two most “anti-establishement” Republicans, Donald Trump and Ted Cruz, blow out their fellow politicians with a majority of “False” or “Mostly False” comments.
The figure below shows an aggregated view of the total proportion of True and False comments made by each entity, which clearly shows the disparities between Democrats and Republicans.
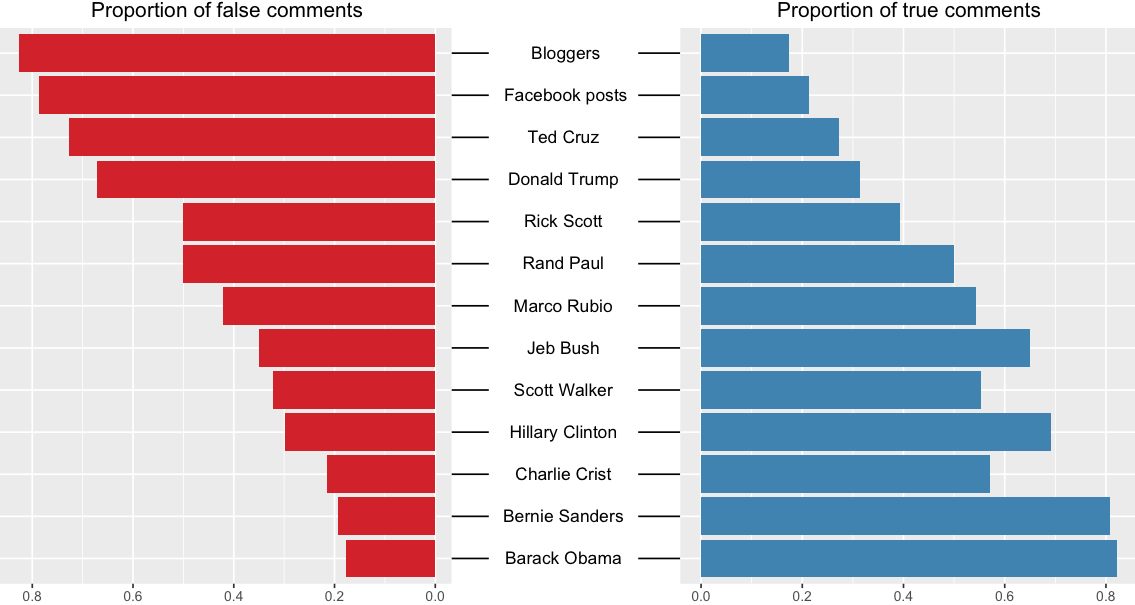
At this point, it is important to raise a potential caveat of this analysis, which is that we are unaware of amy potential bias within the Politifact data. It is conceivable that the people curating the comments are democratic-leaning, or that the sample of comments taken for each entity is not representative. My prior opinion makes me think that this is not the case, but unfortunately I have no data to back this up.
Building the Politifact web app
The next step was to build a Shiny app that would allow anyone to perform head-to-head comparisons between individuals in the Politifact data. For simplicity, I have hosted the app on shinyapps.io, but in order to ensure full reproducibility, I have also “containerized” the app using Docker. If you have not used or heard of Docker, their own website gives a very good description:
Docker containers wrap up a piece of software in a complete filesystem that contains everything it needs to run: code, runtime, system tools, system libraries – anything you can install on a server. This guarantees that it will always run the same, regardless of the environment it is running in.`
With that in mind, the simplistic development workflow used to create the web app was:
- Build the shiny app locally (i.e. on your local machine) and ensure that everything works just as expected.
- Create a file called
Dockerfile, which we will use to place all the relevant instructions and commands, as well as the environnment variables and configurations that will define our container. - Build and run the Docker container to check that the app behaves as expected. If not, iterate over the steps above until you are satisfied.
- Reap the benefits of fully reproducible software across any computing platform!
The source code for the full web app can be found at the following GitHub repository, and has the following directory structure:
.
├── Dockerfile
├── README.md
├── app
│ ├── politifact_image_source.csv
│ ├── politifact_statements.txt
│ ├── politifact_statements_text.txt
│ ├── server.R
│ └── ui.R
├── requirements.txt
├── scrape_politifact.py
└── shiny-server.sh
1 directory, 10 filesBy cloning this Github directory and typing the commands below, you will be able to have a fully working web app.
# build Docker container with tag name pol_app
docker build -t pol_app .
# run Docker container and mirror port 3838
docker run -p 3838:3838 -t pol_appNote: the above was tested on a Ubuntu machine hosted on DigitlOcean, I’m assuming you will have to slightly tweak things when working on a local machine (i.e. if using something like Boot2Docker.
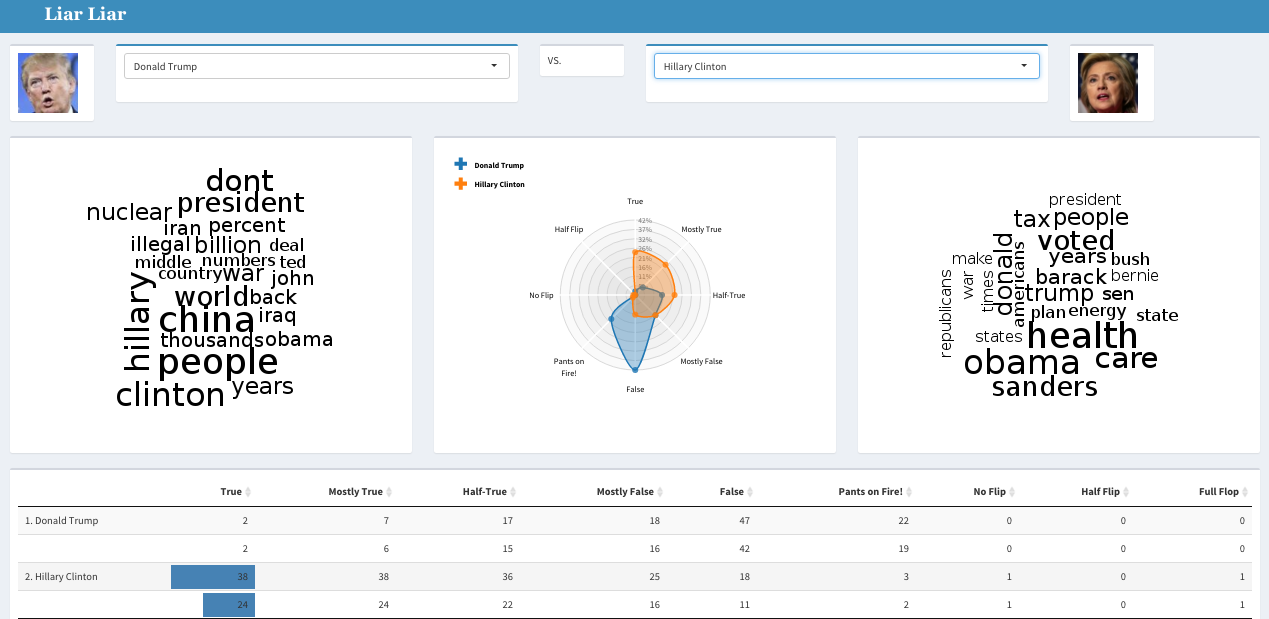
A snapshot of the app is displayed below. It allows to select two political entities and highlights words most often stated by each, along with the overall distribution of types of comments (true, false, etc…) that they made.
Conclusions
We scraped and analyzed Politifact data, a resource that fact-checks statements made by various political entities. We found that statements conveyed via blogs or social media were often misleading. Interestingly, we also uncovered distinct differences between major political figureheads within the Republican and Democratic parties. While it is important to note that the inherent source data may be biased, we found that Democrats were generally more truthful in their political statements. To enable further deep dive of the data, we also build a light-weight app that enables head-to-head comparisons between any pair of entities in the Politifact data. In doing so, we obtained summarized views of the veracity of comments made by entities, as well as the broad topics that they cover.